


In the fast-moving landscape of large language models (LLMs), there are moments that signify a shift in the fundamental economics of intelligence. The release of MiniMax 2.5 (M2.5) is one of those moments. Historically, “Frontier” performance—the kind of reasoning capability required to build autonomous software agents—has been locked behind a “Frontier Tax.” If you wanted a model capable of solving complex, multi-step engineering problems, you had to pay the premium prices of closed-source giants like Claude 4.6 Opus or GPT-5.
MiniMax M2.5 has effectively shattered that ceiling. By delivering Opus-level performance at a 95% discount, MiniMax has moved the industry closer to the elusive “intelligence too cheap to meter.”
1. Performance
The most striking aspect of the M2.5 release is its performance on the most grueling benchmarks in AI today. For a long time, open-weight models trailed behind proprietary ones by a significant margin in coding and reasoning. M2.5 has closed that gap.
The SWE-Bench Verified Milestone
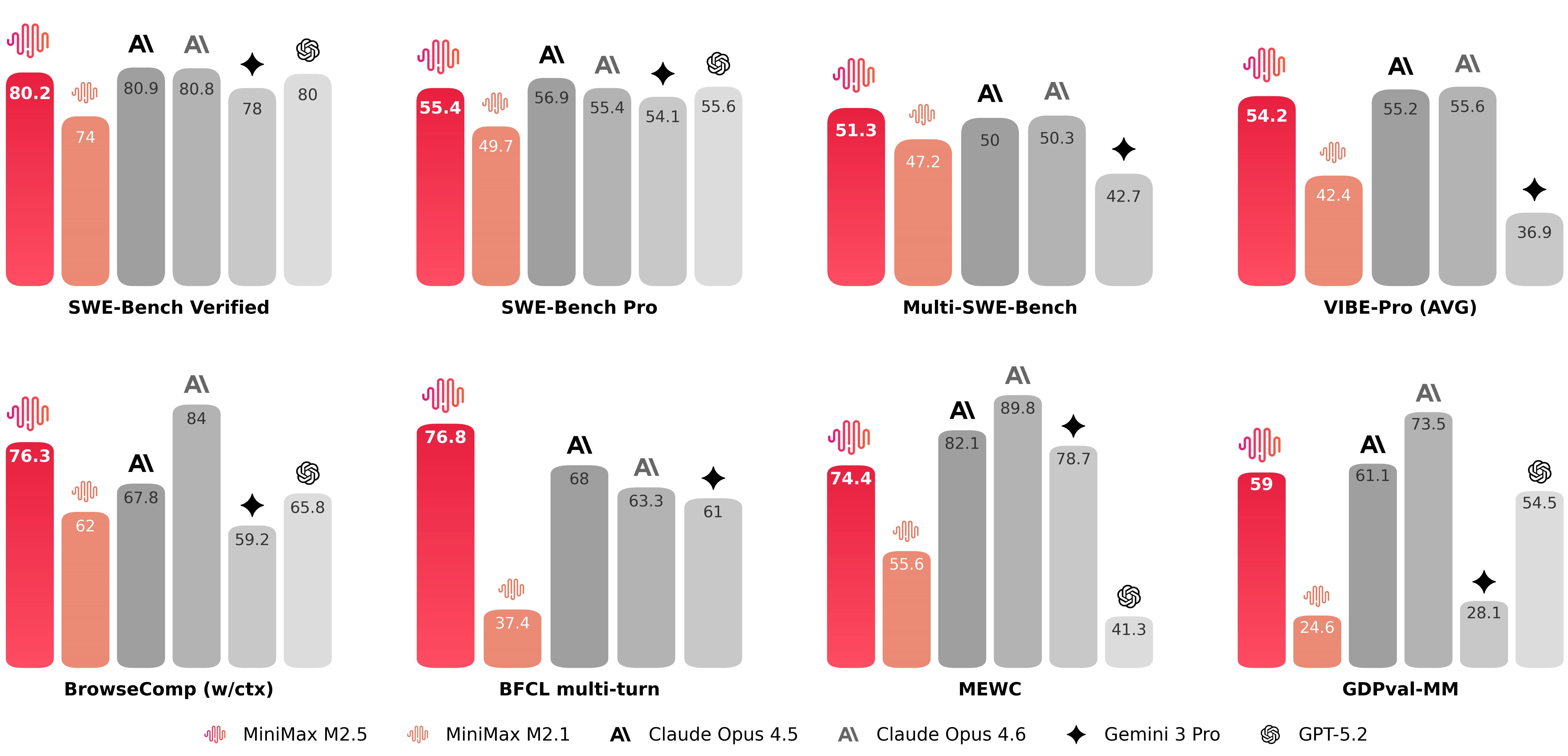
MiniMax M2.5 achieved a staggering 80.2% on SWE-Bench Verified. To put that into perspective, this score places it directly alongside Claude 4.6 Opus, a model that costs nearly 20 times more to operate.
SWE-Bench is widely considered the “Gold Standard” for agentic AI because it doesn’t just ask the model to write a snippet of code; it requires the model to navigate a real-world GitHub repository, understand an issue, and provide a functional fix that passes unit tests. Achieving over 80% suggests that M2.5 isn’t just a chatbot; it is a reasoning engine capable of high-level software engineering.
Dominating the “Agentic” Stack
Beyond pure coding, M2.5 was built for the “Agent Universe”—a term MiniMax uses to describe environments where AI must act autonomously.
BrowseComp (Search Tasks): 76.3%
BFCL (Berkeley Function Calling Leaderboard): 76.8%
Multi-SWE-Bench: 51.3%
These scores indicate a model that excels at “long-horizon” tasks. While many models “fall apart” or lose context after 10 or 15 steps in a workflow, M2.5 is designed to maintain its planning and execution integrity over hours of autonomous operation.
2. Architecture
How does a model achieve Tier-1 performance while remaining efficient enough for cost-effective deployment? The answer lies in MiniMax’s sophisticated Mixture-of-Experts (MoE) and Hybrid-Attention architecture.
The 230B/10B Efficiency Gap
While MiniMax M2.5 contains a massive 230 billion total parameters, it only activates 10 billion parameters during any single inference pass. This makes it the smallest “active” parameter model among all Tier-1 contenders.
The Benefit: If you are self-hosting, the compute and memory requirements are unmatched for its weight class. You can effectively serve M2.5 on hardware (like four H100s) that would struggle to run other frontier models at speed.
Speed: The model can consistently deliver 100 tokens per second (TPS), making it ideal for real-time agentic interactions.
Lightning Attention & The 1M Context Window
Built on the foundations of the earlier MiniMax-M1, M2.5 utilizes Lightning Attention. Standard Transformers suffer from quadratic scaling—the longer the prompt, the slower and more expensive it becomes. Lightning Attention allows M2.5 to natively support a 1 million+ token context window with linear efficiency.
Key Impact: This allows developers to feed entire codebases, massive legal documents, or hours of meeting transcripts into the model without losing performance or breaking the bank.
3. The CISPO Algorithm: Reinforcement Learning for Reasoners
A major breakthrough in M2.5 is its post-training methodology. MiniMax utilizes a proprietary reinforcement learning algorithm called CISPO (Clipped Importance Sampling Policy Optimization).
Standard RL algorithms like GRPO can sometimes suppress “critical tokens”—those “aha!” moments or “wait, let me re-check” thoughts that happen during complex reasoning. CISPO solves this by clipping the importance sampling weights while preserving the gradient updates for low-probability but high-impact tokens.
The Result: M2.5 has “learned” to be a more mature decision-maker. It handles task decomposition more effectively, creating specifications and UI designs before it ever starts writing code. It is a model that “thinks before it speaks.”
+1
4. Disruptive Economics: The $1 Per Hour Agent
For enterprise developers, the most important metric isn’t a benchmark score—it’s the API bill. Building an agentic setup that runs autonomously for hours using Claude 4.6 Opus can cost hundreds of dollars per day.
MiniMax M2.5 changes the math entirely:
Pricing: $0.30 per 1 million input tokens / $1.20 per 1 million output tokens.
Real-world cost: At 100 tokens per second, you can run a high-performance agent for roughly $1 per hour.
This price point enables a “Swarm” approach to AI. Instead of hiring one expensive “Frontier” agent, a company can now deploy 20 “M2.5” agents for the same price, each focusing on a different part of the stack, without sacrificing the quality of the output.
5. Real-World Use Cases: Beyond the Chatbot
MiniMax M2.5 isn’t just for terminal-based coding. It has been trained across 200,000+ real-world digital environments, making it a “multilingual” powerhouse in the office suite.
The “Office Scenarios” Performance
Internal evaluations show M2.5 reaching fluency in:
Excel Financial Modeling: Creating complex formulas and inter-linked spreadsheets.
PowerPoint Automation: Designing presentation structures and generating content.
Cross-Platform Workflows: Seamlessly context-switching between web browsers, IDEs, and desktop applications (Windows, Android, iOS).
Developer Integration
MiniMax has released M2.5 with full support for the modern AI developer stack:
Open Weights: Available on GitHub for local deployment.
Inference Engines: Optimized for vLLM and SGLang.
Third-Party Providers: Already integrated into OpenRouter and OpenHands.
6. Is it Truly “Better” Than Opus 4.6?
The release of M2.5 doesn’t mean proprietary models are obsolete. There are still areas where closed models like Opus 4.6 or GPT-5 hold an edge, particularly in multimodal tasks (as M2.5 remains primarily a text/code specialist) and in absolute zero-shot generalization on niche academic topics.
However, for agentic coding, autonomous research, and workflow automation, the trade-off is clear. If a model provides 99% of the capability at 5% of the cost, the 5% model wins for production scaling.
Criticisms & Limitations
No model is perfect. Early users have noted that M2.5 can be verbose, sometimes generating more tokens than necessary to arrive at a solution. There are also occasional “hallucinations” in complex git operations (such as pushing to a wrong branch). But given the speed and cost, these are minor hurdles that can often be solved with better system prompting or “reflection” loops.
Conclusion
MiniMax M2.5 is more than just another model; it is a signal that the gap between open-weight and proprietary AI has effectively vanished in the domains that matter most for the future of work: coding and agents.
As we move further into 2026, the success of MiniMax—now one of the fastest AI companies to reach IPO status—suggests that the “Agent Universe” will be built not on the most expensive chips, but on the most efficient architectures.
References
https://www.minimax.io/news/minimax-m25