


As of early 2026, the landscape of Retrieval-Augmented Generation (RAG) and semantic search has shifted from “bigger is better” to “flexible is faster.” At the heart of this shift lies Matryoshka Representation Learning (MRL), an elegant training technique that has effectively solved the “fixed-dimension bottleneck” that plagued vector databases for years.
If you’ve ever felt the pain of choosing between a 1536-dimension vector (high accuracy, high cost) and a 128-dimension vector (fast, but “dumb”), MRL is your new best friend. Here is a deep dive into the world of Matryoshka Embeddings.
1. The Fixed-Dimension Paradox
Before 2024, embedding models were rigid. If you trained a model to output 768 dimensions, you were stuck with 768 dimensions.
This created a massive engineering headache:
Storage Bloat: 10 million documents at 3072 dimensions (like OpenAI’s
text-embedding-3-large) requires roughly 120GB of RAM just for the vectors.Latency: Calculating cosine similarity on high-dimensional vectors is computationally expensive, leading to slower query times.
The “Re-indexing” Nightmare: If you decided midway through a project that your vectors were too big, you had to re-embed your entire dataset—a process that could cost thousands of dollars and days of compute time.
We needed a way to make embeddings “elastic.” We needed a vector that could be a heavyweight champion when accuracy mattered, but a lightweight sprinter when speed was the priority.
2. What is Matryoshka Representation Learning?
The name comes from the Matryoshka, or Russian nesting doll. In a Matryoshka set, you have a large doll that contains a smaller, perfectly formed doll inside, which contains an even smaller one, and so on.
In the context of machine learning, Matryoshka Representation Learning (MRL) is a training paradigm where a single embedding is structured such that its most critical semantic information is “front-loaded” into the first few dimensions.
Instead of the information being spread randomly across 1024 dimensions, MRL forces the model to ensure that:
The first 64 dimensions are a valid, useful embedding.
The first 128 dimensions are even better.
The first 256 dimensions capture most of the nuance.
The full 1024 dimensions provide the ultimate “high-definition” detail.
This means you can truncate a 1024-dimensional vector at the 128th index and still have a functional embedding that outperforms older, fixed-size models.
3. The Technical Engine: How MRL Works
The “magic” isn’t in the model architecture (which is usually a standard Transformer), but in the Loss Function.
In standard embedding training, we calculate a single loss based on the final vector. In MRL, we calculate a Multi-Scale Loss. We take the full vector, slice it at various pre-defined “Matryoshka points,” and calculate the loss for each slice.
The Mathematics of Nesting
Let x be our input. The model F produces a high-dimensional vector:
We define a set of dimensions:
where each
The total loss is the weighted sum of losses at each dimensionality:
Where:
z_{1:m} is the prefix of the vector up to dimension $m$.
L is a standard contrastive loss (like InfoNCE).
c_m is a weighting coefficient (often set to 1 for equal importance).
By optimizing for all these dimensions simultaneously, the backpropagation process forces the model to pack the “essence” of the data into the earliest dimensions. If the model fails to capture the core meaning in the first 64 dimensions, the term will be high, and the model will be penalized.
4. Why 2026 is the Year of MRL
While the original MRL paper was published by researchers at the University of Washington and Google in 2022, it didn’t become an industry standard until late 2024 and throughout 2025.
Today, in 2026, nearly every major embedding provider supports MRL natively:
OpenAI: Their
text-embedding-3-large(3072 dimensions) can be truncated to 256 dimensions while still outperforming the legendarytext-embedding-ada-002.Google Gemini: The
Gemini Embedding 2model uses MRL to allow seamless transitions between 768 and 3072 dimensions.Voyage AI & Jina: Models like
Voyage MM-3.5andJina v4have pushed MRL into the multimodal space, allowing you to truncate image and text vectors with less than 1% loss in accuracy.
2026 Benchmarks: The “98% Rule”
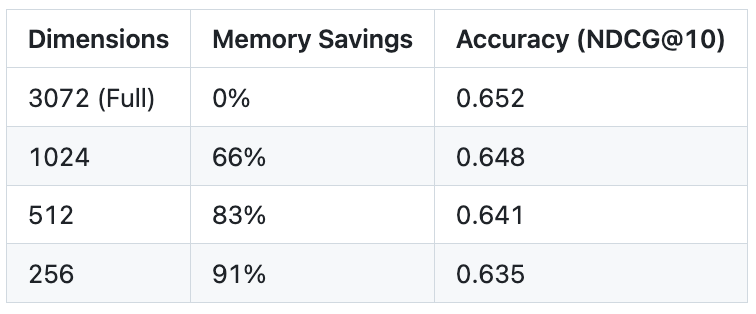
Recent benchmarks on the MTEB (Massive Text Embedding Benchmark) show a consistent pattern: MRL-trained models typically retain 98% of their performance even when truncated to 8-10% of their original size.
5. Engineering the Two-Stage “Coarse-to-Fine” Retrieval
The most powerful application of MRL is the Two-Stage Retrieval pipeline. This pattern allows you to have your cake (speed) and eat it too (accuracy).
Stage 1: The “Coarse” Shortlist
You store only the first 128 dimensions of your embeddings in a fast, in-memory vector index (like HNSW or DiskANN). Because the vectors are tiny, you can search through millions of documents in microseconds. This returns a “shortlist” of, say, 1,000 candidates.
Stage 2: The “Fine” Rerank
You then fetch the full 3072 dimensions for only those 1,000 candidates (stored in cheaper SSD storage). You perform a final similarity check using the full vectors to pick the top 10.
The result? You get the accuracy of a massive model with the infrastructure cost of a tiny one. In production environments, this has been shown to reduce vector search latency by up to 80%.
6. Advanced Trends: SMRL and Adaptive Selection
As we’ve moved into 2025-2026, researchers have introduced Sequential Matryoshka Representation Learning (SMRL) and SMEC (Sequential Matryoshka Embedding Compression).
These new methods solve a subtle issue with original MRL: gradient variance. When you train with 10 different loss functions at once, the gradients can get “noisy.” SMRL uses a sequential training approach that stabilizes the learning process, allowing for even better performance at extremely low dimensions (like 32 or 64).
Additionally, Adaptive Dimension Selection (ADS) modules now allow systems to dynamically choose the embedding size based on the “difficulty” of the query. Simple queries (e.g., “What is a cat?”) use 128 dimensions, while complex, nuanced queries (e.g., “Legal precedents for intellectual property in synthetic biology”) automatically trigger a full-dimensional search.
7. Conclusion
Matryoshka Embeddings represent a fundamental shift in how we think about data representations. We are moving away from “one-size-fits-all” vectors toward liquid representations that adapt to our hardware, our budget, and our latency requirements.
In 2026, if you aren’t using MRL in your RAG pipeline, you’re likely overpaying for your database and overcharging your users in latency.